4 Data Annotation: The Foundation of Deep Learning Models
Goals
This session explores the critical role of training data in deep learning, focusing on data annotation methods, tools, and strategies for acquiring high-quality data. Participants will learn how well-annotated data supports effective deep learning models, understanding the challenges and best practices in data annotation. By the end, participants will be equipped to prepare their datasets for deep learning.
Key Elements
Training data’s role, annotation methods/tools, annotated data’s importance, annotation challenges, annotation best practices, dataset preparation
4.1 Annotation Fundamentals
4.1.1 Fueling intelligence: It’s All About the Data!
The modern AI renaissance is driven by the synergistic combination of Computing advances, more & better data for training, and algorithmic innovations.

Each of these is critical, but you really can’t overstate the importance of massively upscaling training and validation data. Indeed, to a large extent, the most important recent advances in algorithms and computing have been those that allow us to efficiently use huge amounts of data. The more data available, the better the model can learn.
Remember that in Machine Learning:
- You are building a model to produce some desired output for a given input. Imagine you have an aerial photo that contains a water body, or a camera trap video that contains a bear, or an audio recording that captures the song of a particular bird species. In each case, you want the model to correctly detect, recognize, and report the relevant feature.
- To achieve this, you do not build this model by instructing the computer how to detect the water body, bear, or bird species. Instead, you assemble many (often many, many!) good examples of the phenomena of interest, and feed them to an algorithm that allows the model to adaptively learn from these examples. In practice, there may be rule-based guardrails, but we can talk about that separately later in the course.

Much of this course is about understanding what kinds of model structures and learning algorithms allow this seemingly magical learning to happen inside the computer, and what the end-to-end process looks like. But for now, we are going to focus on the input data. And as we embark, it is essential that this core concept makes sense to you:
For any project involving the development of an AI model, you will quite likely be starting with a generic algorithm that has limited or even zero specific knowledge of your particular application area. Unlike with “classical” modeling, the way you will adapt it to apply to your project is not by hand-tweaking parameters or choosing functional forms describing your phenomenon of interest, but rather by exposing this generalized algorithm to many relevant examples (positive and negative) to learn from.
Bottom line, much like vehicles without fuel, even the best training algorithms in the world will just sit and gather dust if they don’t have sufficient data to learn from!

{kind=link}
Ultimately, although you will need to have an understanding of algorithms and models, and learn how to operationalize them on compute platforms, your success in applying AI (especially if you are training and/or fine-tuning models, rather than simply applying pre-trained models) will depend on your ability to implement a robust and effective data pipeline, from data collection methods to data annotation to data curation.
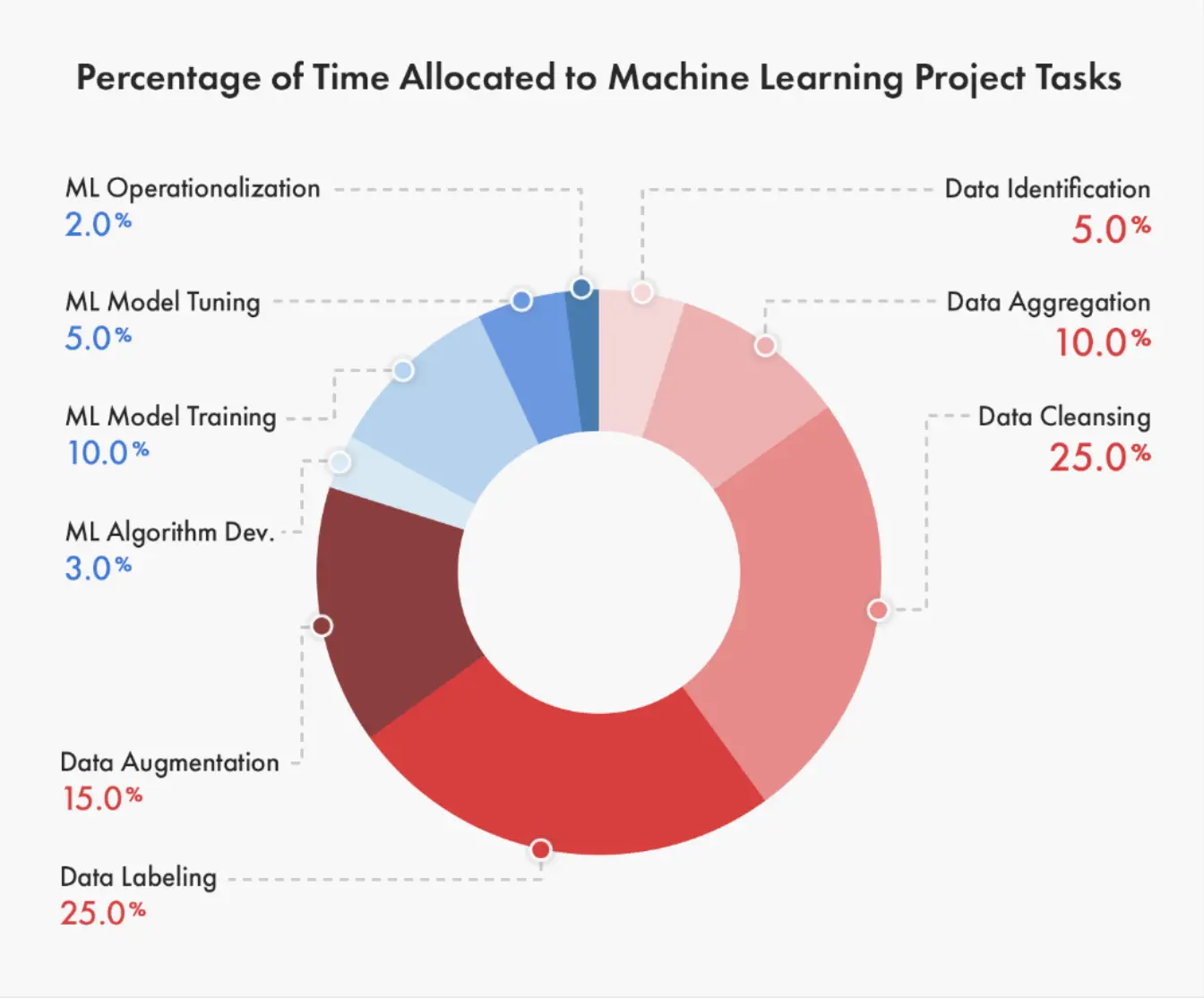
In this module, we focus on data annotation.
4.1.2 What is annotation?
Data annotation is the process of labeling or marking up data with information that is not already explicit in the data itself.
In general, we do this to provide important and relevant context or meaning to the data. As humans, especially in knowledge work, we do this all the time for the purpose of sharing information with others.

In the context of Machine Learning and AI, our objective is to teach a model how to create accurate and useful annotations itself when it encounters new, unannotated data in the future. In order to do this, we need to provide the model with annotated examples that it can train on.
To put it a different way, annotation is the process of taking some data just like the kind of data you will eventually feed into the model, and attaching to it the correct answer to whatever question you will be asking the model about that data.
Simply put, annotation refers to labeling data with information that a model needs to learn, and is not already inherently present in the data.
The term “annotation” is synonymous with “labeling.”
4.1.2.1 Examples
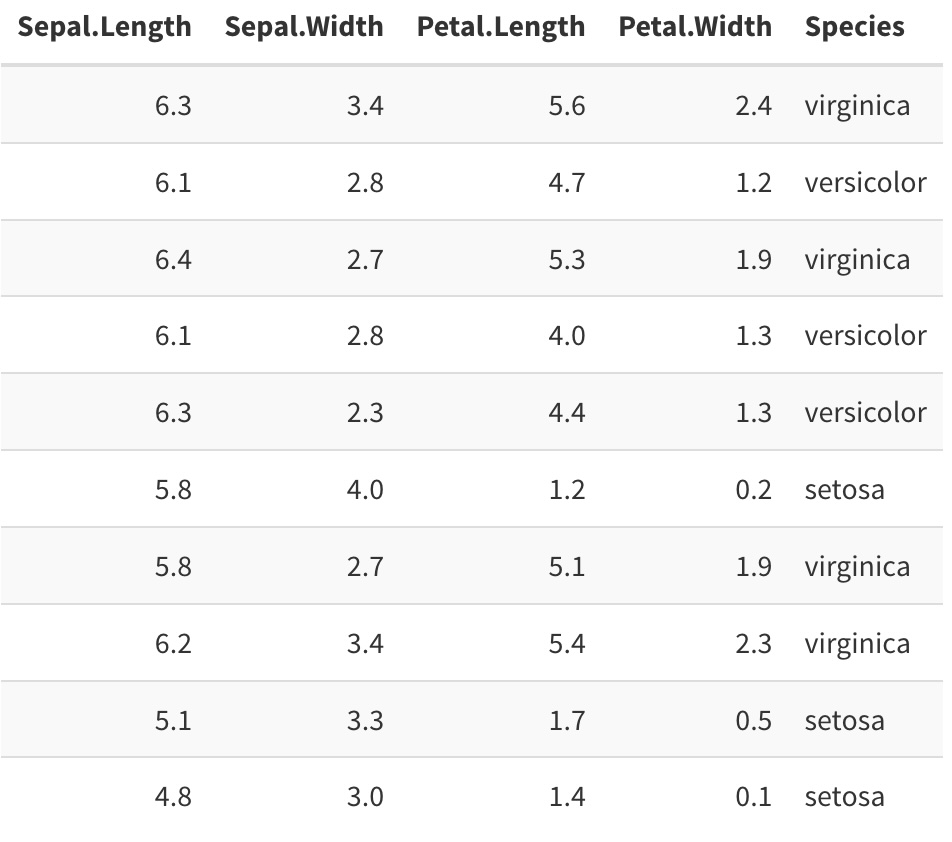
- Label (aka Target) column: Species
When working with tabular data, we don’t usually talk about “annotating” the data. Nevertheless, the concept of labeling for supervised learning tasks (such as classification and regression) still applies, and indeed it’s common practice to refer to the data used for classification and regression model training as “labeled data”. Labeled tabular data contains a column designated as the target for learning, i.e. the column containing the value that a model learns to predict. Depending on the context (and background of the writer/speaker), you might also hear this referred to as the label, outcome variable, dependent variable, or even just y variable. If this is not already inherently present in the dataset, it must be added by an annotator before proceeding with modeling.

- Sentiment: Positive
- Parts of speech: most::adv, beautiful::adj
- Named entity: Alaska

- Voice recognition
- Speech to text

Like image annotation, but with many frames! The focus is often on tracking movement of objects, detecting change, and recognizing activities.
4.1.3 Why is annotation so important?
We’ve already talked about the critical role of data overall in enabling supervised learning, and the role of annotation in explicitly adding or revealing the information in the data.

More specifically, the annotated data will be used at training time, when a specific learning algorithm will use the information in your annotated data to update internal parameters to yield a specific parameterized (aka “trained”) version of the model that can do a sufficiently good job at getting the right answer when exposed to new data that it hasn’t seen before, and doesn’t have labels.
The overall volume and quality of the annotations will have a huge impact on the following characteristics of a model trained on those data:
- Accuracy
- Precision
- Generalizability
Obviously, there is a bit of tension here! The point of training the model is do something for you. But in order for the AI to be able to do this, you have to first teach it how, which means doing the very thing that you want it to do.
Think of it like hiring a large team of interns. Yes, it takes extra startup time to get them trained. But once you do that, you’re able to scale up operations far beyond what you could do on your own.
This raises a few questions that we’ll touch on as we proceed through the course:
- Is there a model out there that already knows at least something about what I’m trying to do, so I’m not training it from scratch? Maybe yes! This is a benefit that foundation models (and more generally, transfer learning) offer. To build on the human intern analogy, if you can hire undergrad researchers studying in a field relevant to the task, you’re likely to move much faster than if you hired a 1st grader!
- How much annotated data do I need? Unfortunately, there is no simple answer. It depends on the complexity of the task, the clarity of the information, etc. So, as we’ll discuss, best practice is to proceed iteratively.
4.1.4 Annotation challenges
By now, it should be clear that your goal in the data annotation phase is to quickly and correctly annotate a large enough corpus of inputs that collectively provide an adequate representation of the information you want the model to learn.
Here are some of the key challenges to this activity:






Labeling of satellite imagery brings its own specific challenges. Consider:
- Scenes are often highly complex and rich in detail
- Geographic distortion: Angle of sensor
- Atmospheric distortion: Haze, fog, clouds
- Variability over time:
- What time of day? The angle of the sun affects visible characteristics
- What time of year? Many features change seasonally (e.g., deciduous forest, grasslands in seasonally arid environments, snow cover, etc.)
- Features change! Forests are cut, etc. Be mindful of the difference between labeling an image and labeling a patch of the Earth’s surface.
- It’s often desirable to maintain the correspondence between pixels and their geospatial location, for cross-reference with maps and/or other imagery
4.1.5 Annotation best practices
This list could certainly be longer, but if you remember and apply these practices, you’ll start off on a good foot.
4.2 Image Annotation Methodology
It’s important to understand and recognize the difference between image annotation types, tasks, and methods. Note that this isn’t universal or standardized terminology, but it’s pretty widespread.
In this context:
- An annotation type describes the specific format or structure of the annotation used to convey information about the data critical for supporting the task.
- An annotation task is the specific objective that the annotations are meant to support, i.e., the job you want your AI application to do. In the computer vision context, this typically means identifying or understanding something about an image and conveying that information in some specific form.
- An annotation method refers to the process or approach used to create the annotations.
4.2.1 Image Annotation Types
The type of annotation you apply will depend partly on the task (see next section), as different annotation types are naturally suited for different tasks. However, the decision will also be driven in part by time, cost, and accuracy considerations.
Tags are categorical labels, words, or phrases associated with the image as a whole, without explicit linkage to any localized portion of the image. 
- Label: beach
- Caption: “Embracing the serenity of the shore, where the sky meets the ocean #outdoor #beachlife #nature”
Bounding boxes are rectangles drawn around objects to localize them within an image. 
Typically, they are axis-aligned, meaning two sides are parallel with the image top/bottom, and two sides are parallel with the image sides, but sometimes rotation is supported.
Generalizing the bounding box concept, polygons are a series of 3 or more connected line segments (each with definable end coordinates) that form a closed shape (i.e., the end of the last segment is the beginning of the first segment), used to more precisely localize objects or areas by outlining their shape. 
Segmentations involve assigning a class label to individual pixels (or collectively, to regions of individual pixels) in an image. Segmentation may be done either fully for all pixels or partially only for pixels associated with phenomena of interest.
In practice, segmentations are produced either by drawing a polygon to circumscribe relevant pixels or using a brush tool to select them in entire swaths at a time

Keypoints are simply points used for denoting specific landmarks or features (e.g., skeletal points in human pose estimation). 
Polylines are conceptually similar to polygons, but they do not form a closed shape. Instead, the lines are used to mark linear features such as roads, rivers, powerlines, or boundaries. 
3D cuboids are bounding boxes extended to three dimensions. These are often used in LiDAR data, which contain a 3-dimensional point cloud, but can also be used to indicate depth of field in a 2D image when the modeling task involves understanding position in three dimensions. 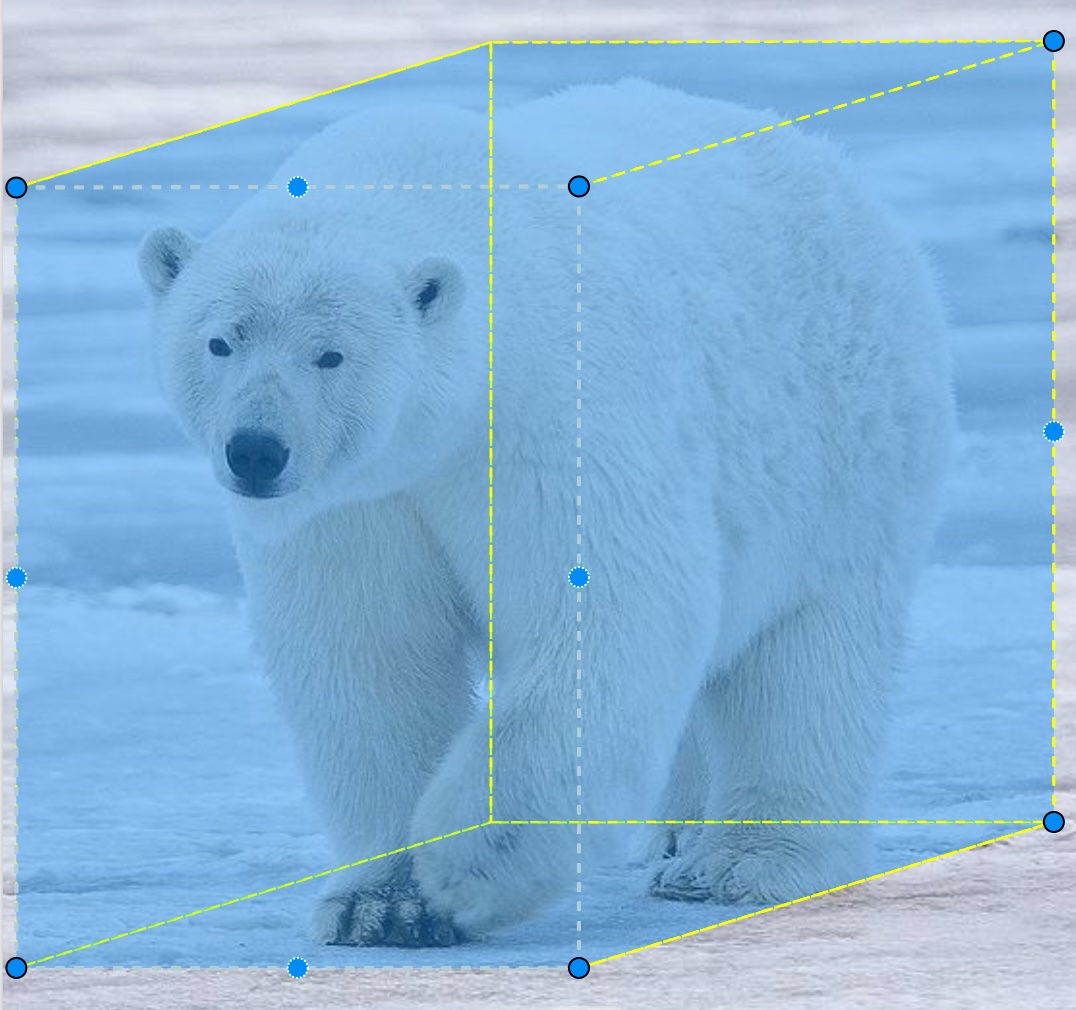
4.2.2 Image Annotation Tasks
The task you choose will depend on the type of information you want the model to extract from the images. Here are the key types of annotation tasks in computer vision:
Segmentation is the task of associating individual pixels with labels for the purpose of enabling detailed image analysis (e.g., land-use segmentation). In some sense, you can think of it as object detection reported at the pixel level.
There are three distinct kinds of segmentation, illustrated below for the following image:

Semantic Segmentation assigns a class label to each pixel in the image, without differentiating individual instances of that class. It is best for amorphous and uncountable “stuff”. In the image below, notice the segmentation and separation of the foreground grass from the background trees from the water in the middle. Also notice that the bears are all lumped together in one segment.

Instance Segmentation separately detects and segments each object instance. It’s therefore similar to semantic segmentation, but identifies the existence, location, shape, and count of objects. It is best for distinct and countable “things”. Notice the four separately identified bears in the image below:

Panoptic Segmentation) combines semantic segmentation + instance segmentation by labeling all pixels, including differentiation of discrete and separate objects within categories. Notice the complete segmentation in the image below, including both the various background types as well as the four distinct bears.

For more on Panoptic Segmentation, check out the research publication.
4.2.3 Image Annotation Methods
The annotation method largely boils down to whether annotations are done manually versus with some level of supporting automation. Ultimately, the choice involves project-specific determination of the cost, speed, and quality of human annotation relative to what can be achieved with available AI assistance.
4.2.4 Data Annotation Workflow
First step: Get a sufficiently large and diverse set of data to annotate and subsequently train on.
You may already have a set of images from your own research, e.g., from a set of camera traps or aerial flights. Or perhaps you already have a clear use case around detecting features in a particular satellite dataset, and have already procured the imagery. If so, great.
If you don’t have your own imagery – and maybe even if you do – you may want to consider augmenting it with additional images if you don’t have enough diversity or content in your own imagery. Depending on your use cases, you may want to poke around public mage datasets like ImageNet.

Time to choose your annotation tool/platform!
There are many options, and lots of factors to consider. See the next section for plenty more details.
Before proceeding, it’s almost always useful (some sometimes essential) to apply various preprocessing tasks to your data to make it easeir to annotatate and/or eventually train on.

Here are some categories of common preprocessing tasks:
Reformatting. If relevant, you may need to convert your source images into a better file format for your task. Beyond this, it may be useful to rotate, crop, rescale, and/or reproject your images to get them into a consistent structural format.
Basic data cleaning. - For example, with satellite or aerial imagery, you may find it useful to apply pre-processing steps such as filtering to remove noise, correcting for atmospheric conditions, correcting other distortion, adjusting brightness/contrast/color.
Feature enhancement. Other context-specific transformations may be useful for “bringing out” information for the model (and human annotators) to use, leading to faster and/or better model outcomes. For an example, listen to this story about how careful transformations of Sentinel 2 imagery provided a huge boost in the detection of field boundaries as part of the UKFields project.
As we discussed earlier, before you begin in earnest, it’s critical that you develop specific guidelines for annotators to follow when doing the annotation using the selected tool.
Note: These should be written down! Some annotation platforms provide a way to document instructions within the tool, but if yours doesn’t (and probably even if it does), you should create and maintain your own written documentation

Often this will be based on a combination of prior knowledge and task familiarity. To the extent that nobody on the project has extensive experience with the task at hand, it’s often helpful to do some prototyping to inform development of the guidelines.
It’s time to annotate!

Keep in mind the following image annotation best practices. They may not always hold, but in general:
- Keeping bounding boxes and polygons “tight” to the object:
- For occluded objects, annotate as if the entire object were in view
- In general, label partial objects cut off at the edge
- Label all relevant objects in the image. Otherwise, “negative” labels will hamper model learning.
Above all else, remember, consistency is critical!
Review the annotations for quality, and if needed, refine by returning to an earlier step in the workflow.

Note that although QA is identified here as a discrete stage in the workflow, in practice quality is achieved through deliberate attention at multiple stages in the process, including:
- Initial annotator workforce training before any annotation is done
- Continuous monitoring during the annotation process
- Final post-annotation review
Finalize and output the annotated data for model training.

Typically, you will need to get the data into some particular format before proceeding with model training. If your annotation tool can export in this format, you’re all set. If not, you’ll need to export in some other format and then use a conversion tool that you either find or create yourself.
From here, presumably, you’ll move on to model training!
Remember this key best practice: Iterate! You will almost certainly not proceed through the annotation workflow in one straight shot. Plan to do some annotations, train, test, fix annotations, figure out whether/how to do more and/or better annotations, refine your annotation approaches, etc.
4.3 Annotation Tools & Platforms
4.3.1 High level considerations
Here are some questions you should be asking…
4.3.2 Tools & services galore
Note that for geospatial image data annotation in particular, historically there’s been a divide between these two approaches:
- Mature GIS platforms (QGIS, ArcGIS, etc) -
- First-class geospatial data and imagery support
- Native capabilities for drawing and editing features like points, lines, and polygons
- But all of the menus and heavyweight UI around robust spatial feature management can impede fast & efficient annotation
- Limited or no support for the broader annotation workflow and lifecycle
- Image annotation software and platforms (LabelBox, RoboFlow)
- Really nice and constantly improving
- Mostly generic with respect to supporting annotation for Computer Vision tasks, not full-featured around environmental research applications, especially with respect to Remote Sensing imagery with spatial component, multispectral bands, etc
In between, you’ll find a few dedicated software packages for environmental and/or spatial image annotation. However, because this is a small niche, you’ll find that they’re often rough around the edges, and likely have a very focused (i.e., limited) set of features addressing only the specific use cases of relevance to the development team. On the plus side, usually they are developed as open source projects, so if you’re up for the investment, you may want to consider contributing or extending these tools to meet your needs.
4.3.2.1 Open-Source Tools for Image Annotation
- LabelImg
- High level: An open-source tool for creating bounding boxes.
- Used for object detection mainly, maybe??
- Only supports bounding boxes for annotation
- “Graphical image annotation tool and label object bounding boxes in images”
- It is written in Python and uses Qt for its graphical interface.
- Annotations are saved as XML files in PASCAL VOC format, the format used by ImageNet. Besides, it also supports YOLO and CreateML formats
- See this third-party video tutorial
- VGG Image Annotator (VIA)
- High level: A flexible (but manual) tool for image, video, and audio annotation.
- A serverless web application, runs locally and self-contained in a browser, with no network connection required
- Released in 2016, still maintained, based out of Oxford
- See demo
- Labelme
- Locally installed application written in Python/QT and used for polygonal annotation of images
- See GitHub repo
- Draws inspiration from an older Javscript-based LabelMe web application for image annotation
- IRIS (Intelligently Reinforced Image Segmentation)
- Provides semi-automated annotation for image segmentation, geared toward multi-band satellite imagery
4.3.2.2 GIS platforms with annotation plugins
- QGIS
- ArcGIS
4.3.2.3 Hybrid solutions with both desktop and hosted options
- CVAT (Computer Vision Annotation Tool):
- Open-source tool for video and image annotation, widely used in computer vision projects.
- Uses pre-trained models to assist annotation?
- See GitHub repository
- Also has cloud-based offering and offers annotation services
- Supports:
- 🔥 Label Studio
- Multi-type data labeling and annotation tool with standardized output format
- Works on various data types (text, image, audio)
- Has both open source option and paid cloud service
- See online playground
- Microsoft’s Spatial imagely labeling toolkit
- imglab
4.3.2.4 Commercial apps
- RectLabel
- Offline image annotation tool for object detection and segmentation
- Has regular and Pro version
- Built for Mac
- See support page
4.3.2.5 Commercial services
- Labelbox
- Cloud-based commercial platform, albeit with possible free options for academic researchers
- Roboflow annotate
- Online platform, with limited free tier
- Free tier does not offer any privacy
- SuperAnnotate
- High level: Full-featured collaborative annotation and modeling platform
- Commercial offering with free tier
- MakeSense.ai
- Includes AI models!
- GitHub0
- Supervise.ly (commercial with free version)
- Labelerr (commercial with free researcher tier)
- RMSI annotation tools & services
- Kili annotation platform (see geoannotation docs)
- Segments.ai labeling platform
- Sama
- ScaleAI
- Diffgram (see tech docs and GiHub) – commercial but locally installed? Hard to tell!
- DarkLabel
- Groundwork professional labeling services
4.3.2.6 Fully managed AI & annotation services
4.3.3 Miscellaneous links
- Satellite image deep learning (Robin Cole’s site)
- Open Source Data Annotation & Labeling Tools